Debugging Workflows
Even the most carefully planned workflows can encounter issues. In this guide, we'll learn how to debug workflow failures in LittleHorse by intentionally creating an error and then fixing it.
This tutorial assumes you have completed the Your First WfSpec guide.
Understanding Task Failures
When a task fails in LittleHorse, the workflow execution pauses at that point. This gives you time to:
- Investigate what went wrong
- Fix the underlying issue
- Retry the failed task
Let's see this in action by modifying our greeting Task Worker to fail under specific conditions.
Creating a Test Failure
Let's update our GreetingWorker to throw an exception when greeting a specific name:
package io.littlehorse.tutorial;
import io.littlehorse.sdk.worker.LHTaskMethod;
public class GreetingWorker {
@LHTaskMethod("greet")
public String greet(String name) {
if (name.toLowerCase().equals("anakin")) {
throw new RuntimeException("I don't like sand!");
}
return "Hello, " + name + "!";
}
}
In real applications, task failures might occur due to network issues, database errors, or other system problems. We're using a contrived example here to demonstrate the debugging process.
Triggering and Observing the Failure
Let's run our workflow with the problematic input:
lhctl run getting-started name Anakin
Using the Dashboard
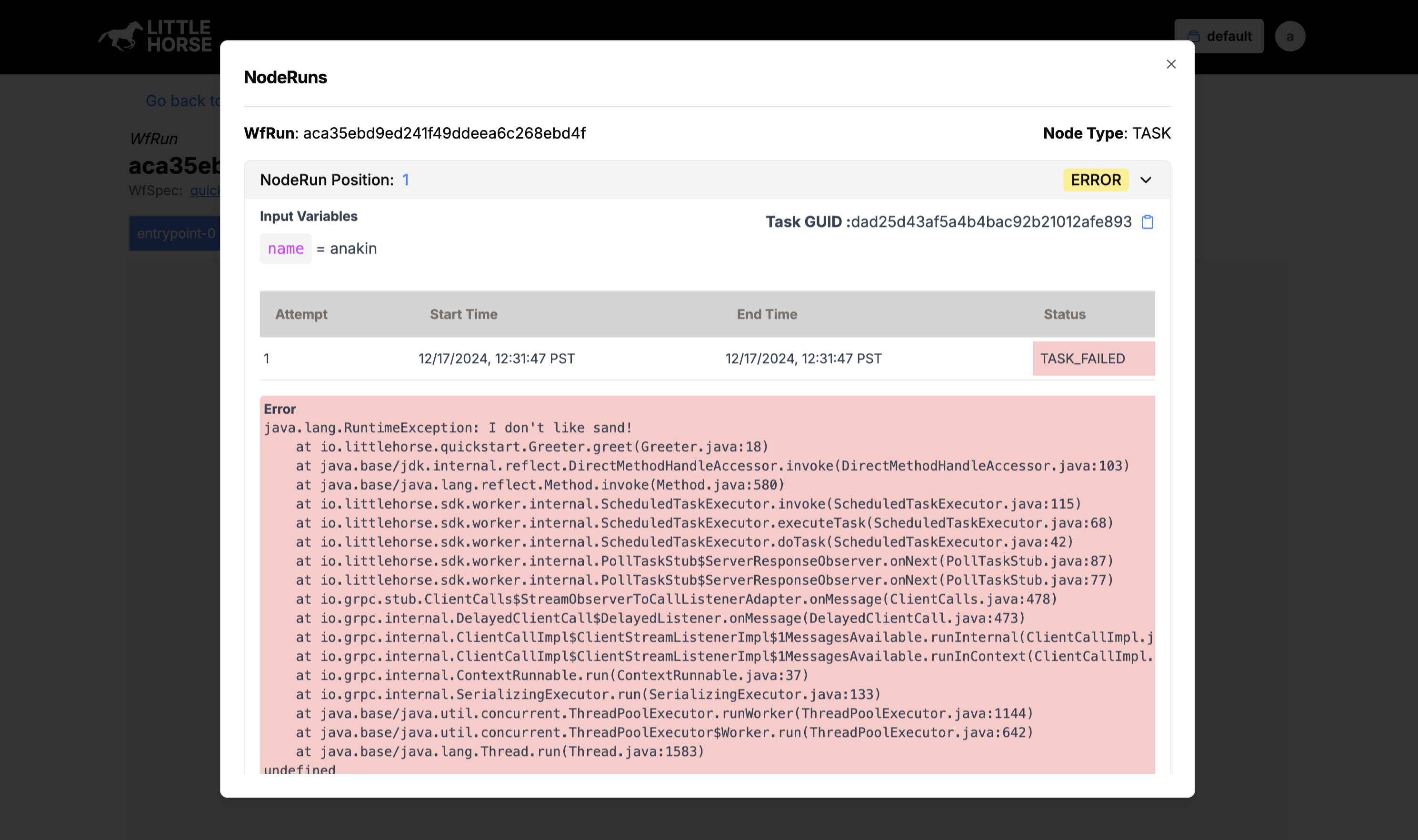
The LittleHorse Dashboard provides a visual way to inspect failures:
- Open
http://localhost:8080 - Navigate to "Workflow Runs"
- Find your failed workflow
- Click on the red node to see:
- The full stack trace
- Input variables
- Failure timestamp
- Node execution history
Using the CLI
You can also inspect failures using lhctl:
# Get the workflow run status
lhctl get wfRun <WORKFLOW_RUN_ID>
# Get detailed information about the failed node
lhctl get nodeRun <WORKFLOW_RUN_ID> <NODE_RUN_ID>
Rescuing Failed Workflows
Once you've fixed the underlying issue (in our case, maybe we decide that we do like sand after all), you can rescue the workflow:
# Retry the failed node
lhctl rescue <WORKFLOW_RUN_ID> <THREAD_RUN_NUMBER>
# Verify the workflow is now proceeding
lhctl get wfRun <WORKFLOW_RUN_ID>
The rescue command tells LittleHorse to retry the failed node. This is particularly useful when the failure was due to a temporary issue or after you've fixed a bug in your task worker.
Best Practices
When debugging workflows:
- Always check the full stack trace to understand the root cause
- Verify input variables were what you expected
- Fix the underlying issue before attempting a rescue
- Consider adding more error handling in your task workers
Wrapping Up
You've learned how to:
- Identify failed workflows in both the dashboard and CLI
- Inspect failure details
- Rescue failed workflows after fixing issues
In the next lessons, we'll explore more advanced workflow patterns and error handling strategies.
If you haven't already:
- Join the LittleHorse Slack Community
- Give us a star on GitHub
- Check out our documentation